基于 MobileNetV2 的端侧水果分类
项目背景
在超市购买蔬菜水果等农产品时,往往需要称重计价。而传统的计价的过程往往需要人工介入,识别商品的类型并输入到机器中。目前,已有通过图像识别商品类型的产品,能够自动识别商品类型并选中单价,称重员确认后即可完成计价过程。
项目将会在嵌入式设备上部署一个能够执行图像分类任务的神经网络,并配合一些相应的外围软件组件来构成一个完整的应用系统。
项目架构和设备选型
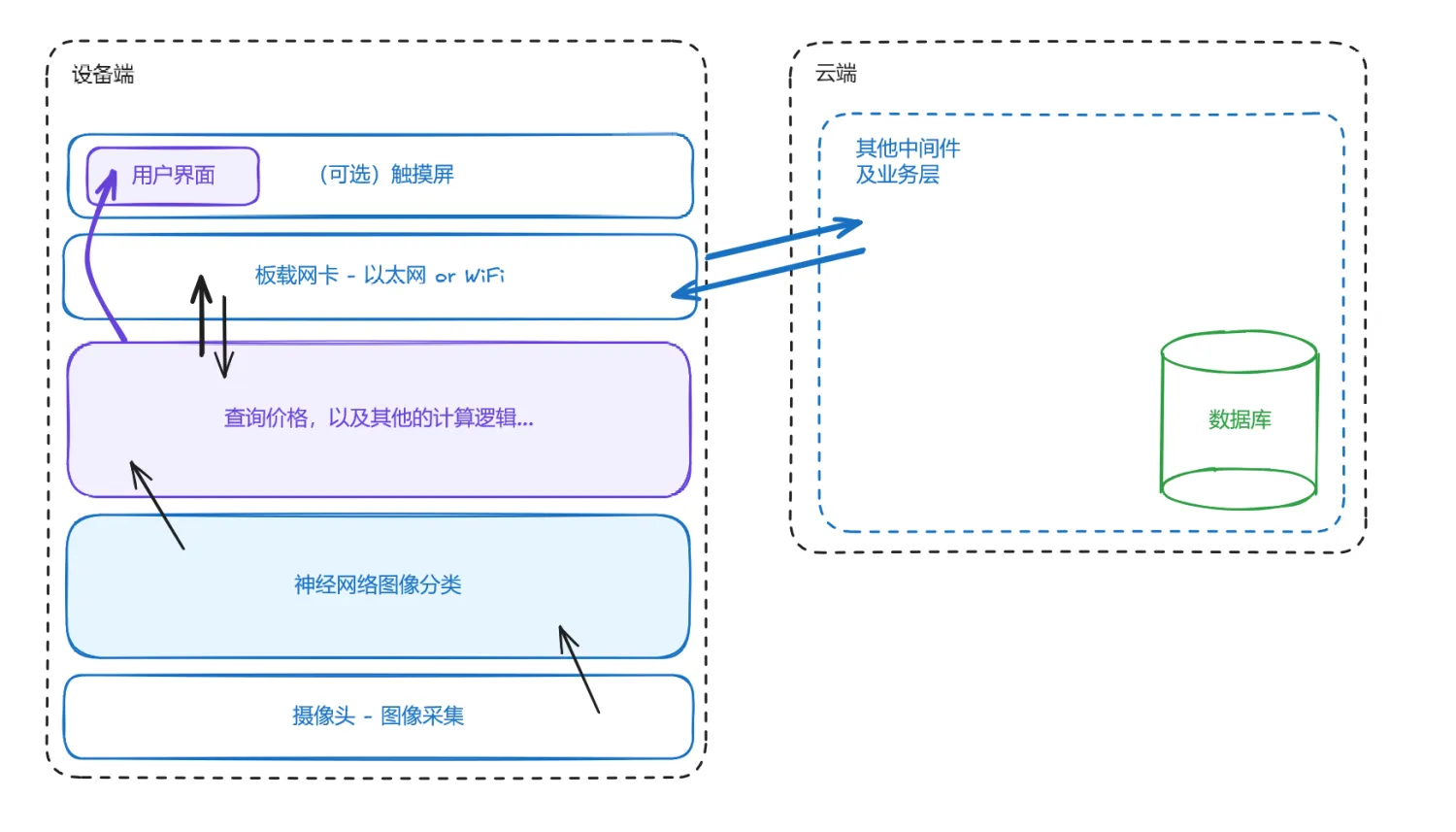
项目分为端侧和云上两个部分。端侧负责进行图像预处理,图像识别和展示结果。数据存储则在云端。端云之间透过网络连接。
本次设计选择瑞芯微的RK3568平台,其具有1TOPS的整数推理性能,同时有相对低廉的价格。具体而言,本次实验在正点原子的开发套件上进行。端侧性能相对强大,能够执行完整的Python环境。出于开发效率考虑,项目代码主要用Python开发。
数据准备
在Kaggle上可以找到一些关于蔬菜水果的数据集。我选择了网站上评分较高的一个数据集Fruit and Vegetables image Dataset 进行测试。这个数据集由社区用户从搜索引擎获得的图片构成。虽然存在小部分质量较低的输入,如包括水果的卡通图片或含有文字或其他图像覆盖等的图像,但这个数据集具有较高的数据多样性,且整体风格契合本次训练的需求。笔者也考察了流行的几个类似的数据集,有的数据集仅包括单个水果或蔬菜的裁剪图像,可能难以泛化到本次的识别任务。
模型选择和微调
本次模型架构选用为移动端高度优化的MobileNetV2.
MobileNetV2
笔者基于Torch Modelhub提供的预训练权重在蔬菜水果数据集上进行微调。并尝试了以下两种策略
- 在模型的feature层后继续增加全连接层,冻结原有模型的所有参数。
- 修改模型classifier层的输出维度,微调原有模型的最后几层。
第一种策略的表现并不好,具体表现为优化到一定程度后,模型的Loss不再降低。可能是因为单层全连接层的表现力并不足以迁移原有的网络输出到新的任务,或者是优化器的参数选择存在问题。
在同样的优化器设定下,第二种策略得到了更好的效果。一般而言,微调任务应当选择比从头训练低一些的学习率,且不需要很长的训练步骤。经过几轮测试,模型能够在测试集上达到92%的分类准确率(top1)。训练配置如下
- 学习率 3e-5
- 优化步数 10
- 解冻特征提取器的最后3层
- Batchsize = 128,启用随机打乱
模型训练在国内深度学习平台AutoDL上进行,显卡型号为Nvidia Tesla T4,进行一轮优化大约需要半小时。
模型转换
嵌入式平台的算力并不如桌面平台。瑞芯微系列平台上的NPU不支持直接运行通用的推理框架, 需要使用厂方提供的RKNN SDK。软件包提供了动态链接库和相应的C++和Python API.
RK的工具包支持多种不同的模型实现方式,但似乎比较靠谱的还是转换为onnx模型再导入,最终输出RK的私有模型格式。
工具包除了编译还提供量化功能,不过笔者测试量化到8bit和不量化的推理速度并没有太大区别。对于图像处理模型,还可以指定模型输入图片的归一化参数,工具包会将归一化烘焙到模型中。部署时的预处理阶段就不再需要归一化计算。
经过测试,量化和不量化几乎没有性能差异。所以笔者选择了不量化直接上板。
上板测试
一开始板上测试的系统选择的是Ubuntu20.04,因为标准的发行版有完整的开发环境和配套工具。但是正点原子提供的镜像缺少无线网卡驱动的内核模块。所以,后来选择了正点原子提供的BuildRoot镜像。
Buildroot镜像并不适合用于直接开发,其上只有Busybox和额外的一些二进制工具。为了能在板上运行Python脚本,需要一些途径来安装依赖运行库,包括OpenCV等。幸运的是,Anaconda除了管理Python库,还能够下载相关的二进制库。安装Numpy, OpenCV等必要依赖之后,板子能够正常调用摄像头或者从本地读取文件执行推理任务。
板上执行测试集推理达到了91.92%的准确率,说明模型转换基本没有精度损失。
接入应用
接入摄像头后,数据的大致流动流程是
- 从摄像头获取一帧
- 执行图像预处理:缩放和中心裁切
- 模型推理
- 处理输出值,转换为标签和概率
- 发送推理结果到云端
利用cv::VideoCapture类库可以方便地从摄像头获取内容。从摄像头获取内容并推理依然具有很高的推理速度。笔者将推理的逻辑部分封装到了一个模型类,利用Flask框架搭建了一个Web服务。这个框架能够同时担任发送静态内容和提供HTTP API两种任务,静态页面在上位机的浏览器中打开,然后定时从服务端拉取当前摄像头图片和相应的推理结果。
笔者目前没有可用于实测的道具,故采用摄像头拍摄屏幕的方法测试。
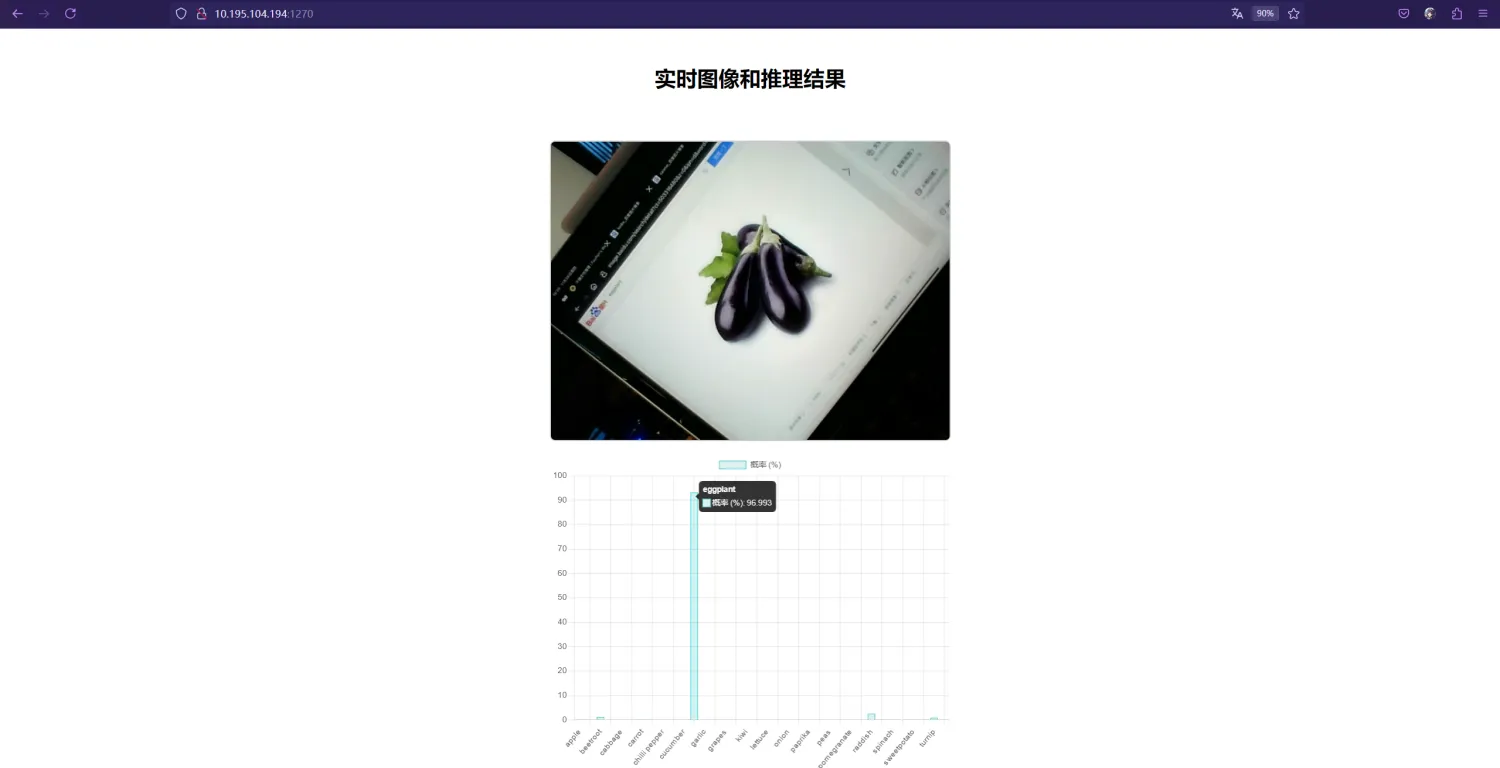
实测结果是,模型具有典型特征的输入能够正确作出响应,但对另外一些测试数据则不能正确给出标签。这可能是因为数据集和下游任务的不匹配导致的,如果能获取或模拟一些下游任务的真实图片对模型进行进一步微调,推理效果会更好。
目前的验证已经证明,板上模型能够高效且较准确执行图像分类问题,但模型表现的提升需要更多数据的支撑。